- >> Softwares
- >> Neural PCA
Neural PCA¶
The equations of the Oja and Sanger learning rules are provided in this document.
Oja’s learning rule¶
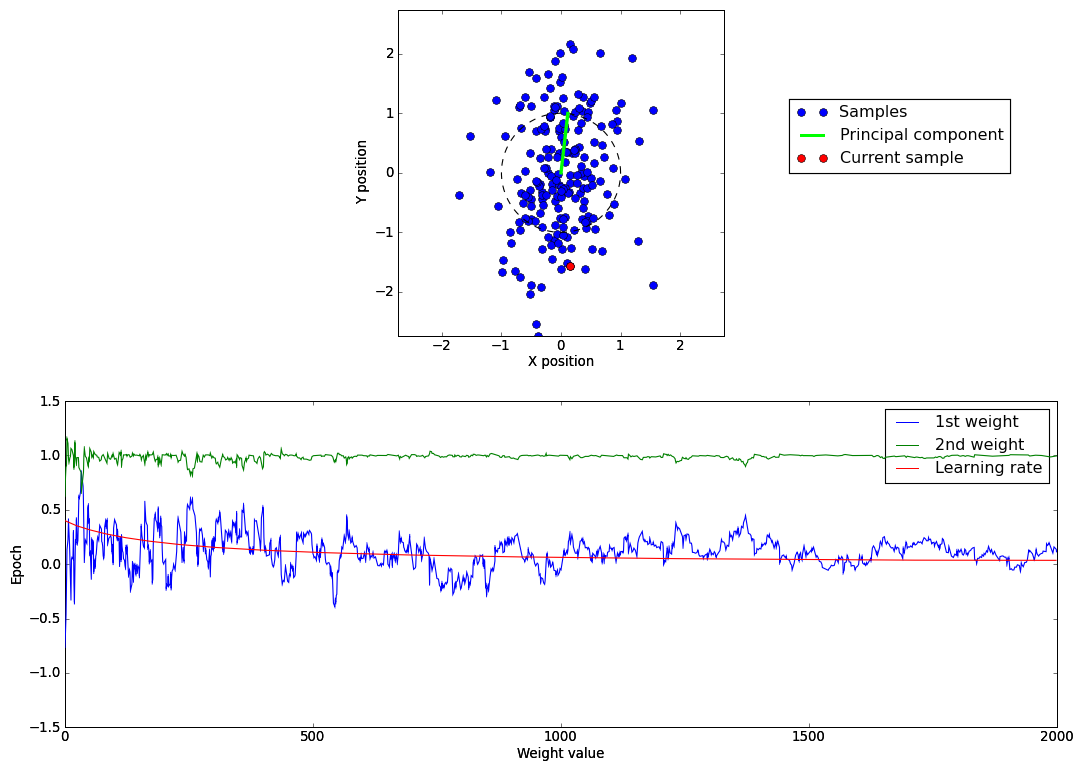
An introduction to the Oja’s learning rule can be found on scholarpedia. The following script oja.py provides a Python demo showing how the Oja’s learning rule can be used to extract the first principal component of a distribution.
Below is an illustration of the demo. In the upper graph, the blue points represent the 2D samples, the red point the currently processed sample, the green line the weight vector of the output neuron and the dotted black circle is of unitary radius showing the normalization of the weights. On the second graph is represented the evolution of the two weights and of the learning rate through the learning epochs. In addition to using the previous learning rule, with a decreasing learning rate, the samples are also centered to have a zero mean.
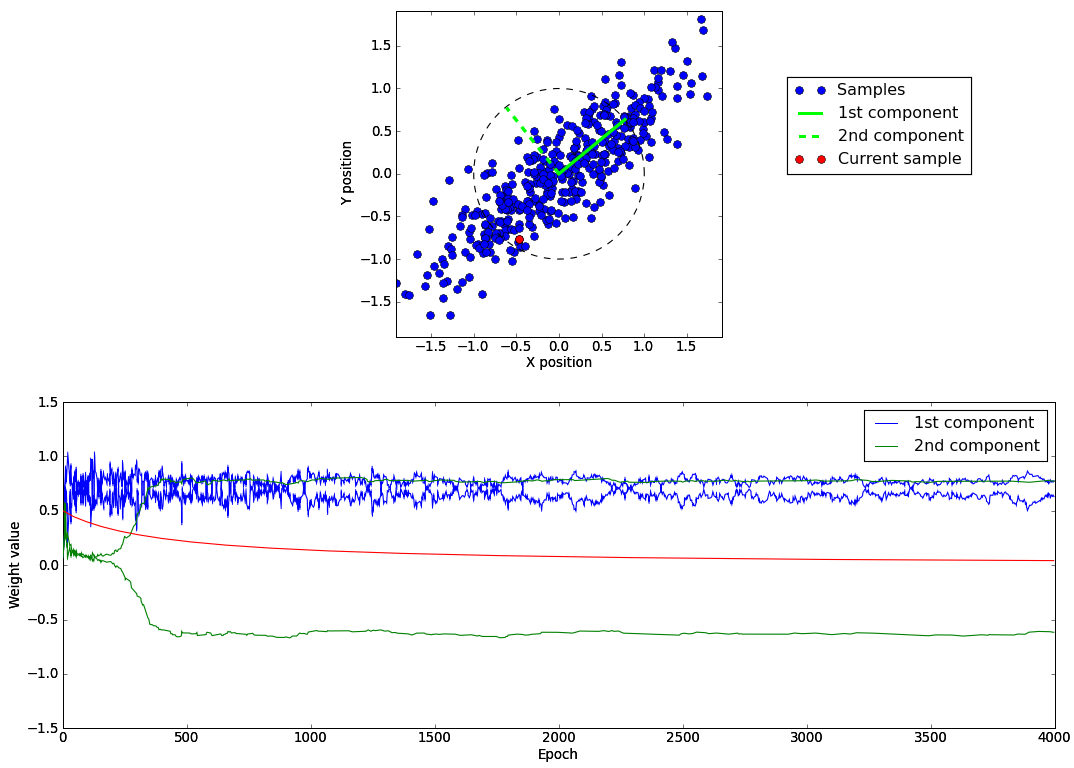
Sanger’s learning rule¶
A description of the Sanger’s learning rule (also called Generalized Hebbian Learning), used to extract several principal components can be found in the thesis of Terence sanger.
The following script sanger.py provides a Python demo showing how the Sanger’s learning rule can be used to extract the two principle components of 2D samples. Below we show an example where two weights vectors have been extracted and we observe that they match the two principale components of our gaussian distribution.